DisPerSion.eLabOrate(d)
- Human/Machine Co-Creation in Collective Performance Contexts: From Instruments to Agents
- Deeply Listening Machines
- post-digital-instruments
- Gesture, Intentionality and Temporality in Machine-Mediated Performance
- Electro/Acoustic Comprovisation: Instruments, Identity, Language, Score
- Distributed Performance: Networked Practices and Topologies of Attention
- Distributed Composition: Networked Music and Intersubjective Resonance
- Distributed Listening: Expanded Presence in Telematic Space(s)
- Expanded Listening and Sonic/Haptic Immersion
dispersion.eLabOrate(D) is the followup to DisPerSion.eLabOrate (2019) and thematically follows the same Deep Listening augmentation – moving the Tuning Meditation from a human centred piece to a shared human/machine collaborative performance. eLabOrate(D) also moves to a telematic setting vs the in person environment from the previous iteration – and constitutes the “D” at the end of the title (elaborate distributed).
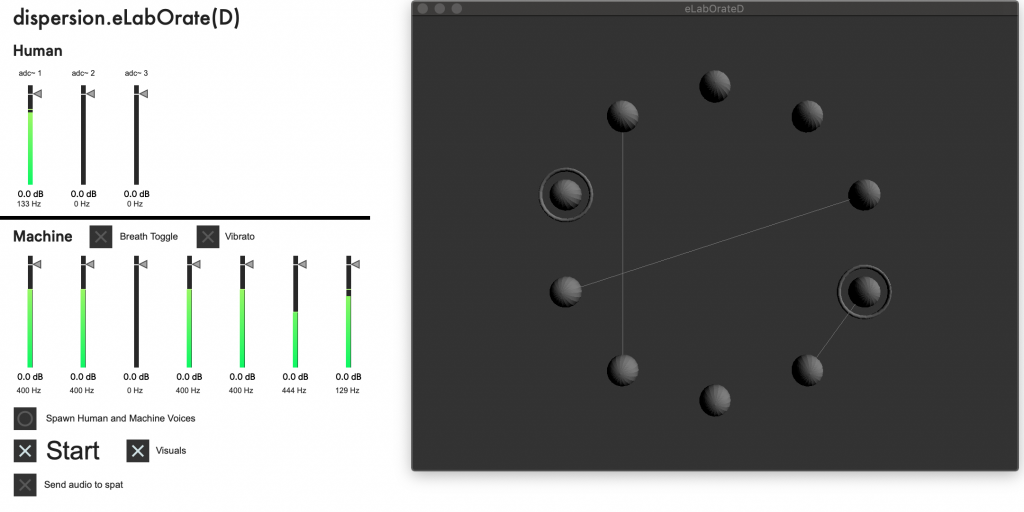
Where the first project shadowed the activity of sound in the space by listening and responded immediately, eLabOrate(D) gives a human time scale of interaction to the machine voices. 0 – 32 machine voices can be spawned to start and each is listening and vocalizing individually, each also within their own breath cycle.
This breath cycle consists of an inhale and exhale, where the machine voice is sounding or silent, and alternates creating a new tone or matching another tone on exhale. As the system is participating in a typically human centred sonic practice, a human-like breath time scale was implemented to give a clear sense of the machine voices moving alongside and in reaction to human participants. This iteration of the work feels much more aligned with sounding and receiving a response from the machine vs the immediate modulation and resynthesis of all sound activity in the space.
Remote players connect through JackTrip to a central hub server hosted on the same machine running eLabOrate(D). Audio signals are analyses individually from each participant to ensure the system hears each voice and tone distinctly. The system keeps track of all used tones from both human and machine players and avoids reusing these for new tones within the machine voices. There is a preset frequency offset in order to keep some distance between used tones and new attempted random values. Matching is done by mimicking the fundamental frequency of any active voice, from again either human or machine. Visualization of the system places individual human and machine players as spheres evenly distributed in a circle. New tones are visualized by a ring around a given voice’s sphere, while matching tones are shown with a line linking the vocalizing sphere and its target.