Intergestura
- Human/Machine Co-Creation in Collective Performance Contexts: From Instruments to Agents
- Deeply Listening Machines
- post-digital-instruments
- Gesture, Intentionality and Temporality in Machine-Mediated Performance
- Electro/Acoustic Comprovisation: Instruments, Identity, Language, Score
- Distributed Performance: Networked Practices and Topologies of Attention
- Distributed Composition: Networked Music and Intersubjective Resonance
- Distributed Listening: Expanded Presence in Telematic Space(s)
- Expanded Listening and Sonic/Haptic Immersion
The Interdependence Gestural Agent
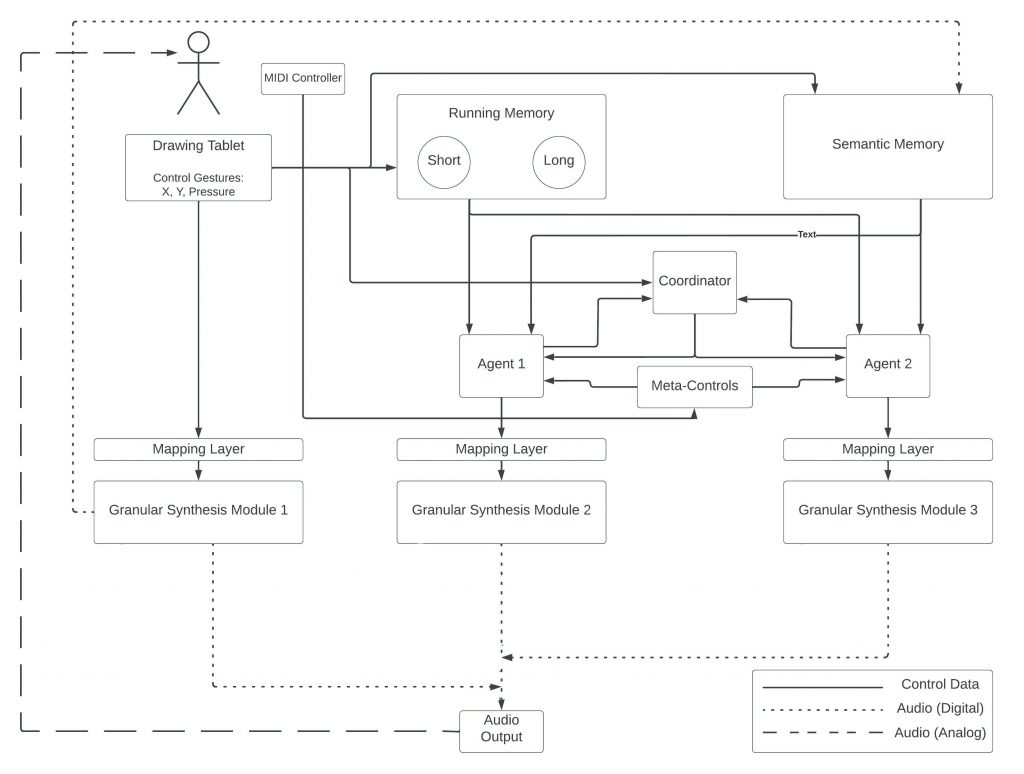
The Interdependence Gestural Agent (Intergestura) is a software agent that improvises and co-creates electroacoustic music with a human performer and other Intergestura agents. The current version of Intergestura works with digital instruments developed in the MaxMSP programming environment. The agent engages in a call and response behaviour with its co-performers according to the instructions composer Pauline Oliveros’ sonic meditation-style text score, Interdependence. Building upon an embodied cognition view of listening in musical performance, Intergestura adapts the original rules of Interdependence towards a gestural approach to understanding musical actions: whereas the original makes reference to short and long ‘pitches’, the rules that Intergestura follows replaces ‘pitches’ with ‘gestures’.

Parallel Memories
Inspired by metaphors of sonic memory from the GREIS and FILTER systems, Intergestura makes use of parallel episodic (running) and semantic memories. In performance, all gestures that the human performer makes are added to the running memory and are classified as either short or long gestures. Gestures that the human explicitly selects are added to the semantic memory. The gestures in the semantic memory are complete sonic gestures – they contain control data, audio, and audio analysis (onset detection). This builds upon a recent lab project to create a performable gestural database.
The agent draws on these two memories to inform its behaviour. When an agent decides that it wants to make a gesture, it selects a gesture from its running memory, performs a time transformation to the gesture (either stretching or compressing it), and plays that gesture back through its corresponding granular-synthesis module. When playing in sender mode, the agent selects one of its semantic memories and uses the distribution of onsets in that gesture to generate a sequence of episodic gestures to play.
An example implementation of Intergestura, demonstrated in the above video, features a human performer playing a granular-synthesis based instrument – called Kin – via a Wacom drawing tablet and MIDI controllers, while two agents each control and play their own instances of the same Kin instrument.
In the Kin implementation, gestures in this memory consist only of Wacom control data – meaning stylus x and y coordinates and pressure. Similar to GREIS, the explicit segmentation of a semantic gesture is done by pressing a button on the stylus at the start of a gesture and again at the end.
Expanded Listening
In addition to the ‘listening’ that happens when storing human-made gestures in their respective memories (short/long classification, onset detection), Intergestura makes use of three other types of expanded listening. Two of these inform the agent when it is performing in receiver mode.
First, in receiver mode, the agent listens for the ends of incoming gestures from the human-player and from any other agents. The agent probabilistically decides if it wants to respond to a given incoming gesture, and requests a type of gesture to respond with (short or long) from the coordinator module. The coordinator module makes use of the second form of expanded listening – it listens to the types of gestures from all the performers and tracks the sequence of short and long gestures. When an agent requests a type of gesture to respond with the coordinator uses a variable Markov model to provide a gesture type based on what it has heard previously. This VMM is initialized randomly and is continuously updated throughout performance so that patterns that emerge in performance become reinforced. When the agent receives a type of gesture to respond with, it performs a k-nn query against the corresponding cluster in the running memory and selects a similar gesture to respond with.
The agent uses its final form of expanded listening in sender mode. Here, the agent listens to the density of all gestures from the other performers. This density informs how fast the agent will step through its generated sequence. If there is a high density of gestures, the agent will step through its sequence more quickly and if the density is lower, the agent steps through slower – this allows the agent to match the current density of gestures from human performer and other agents.
Meta Controls
Each agent has a set of meta controls that influence the agent’s behaviour. These are mapped to a set of MIDI controls and can be adjusted by the human during a performance. Meta controls include the likelihood an agent will respond to a gesture, likelihood of playing in sender or receiver mode, and likelihood of selecting a particular variation. The agents can additionally be synchronized, so that one agent leads in which variation is being played and the other agents follow.
Future Work
Current development of Intergestura is focused on creating a version that works primarily through audio – both to allow performers of purely acoustic instruments to perform and interact with Intergestura as well as to engage in vocal listening/sounding workshops contexts, similar to the dispersion.eLabOrate project.
Publication
Maraj, K. and D. Van Nort, “Intergestura: a gestural agent based on sonic meditation practices”, in Proc. of the International Conference on Computational Creativity (ICCC), 2022.